




Table of contents
When you open your browser and enter www.google.com in the URL bar, it processes your request and loads up a new page. Have you ever wondered how that works? How does the browser get access to the page you see when you enter that URL? In this article, I aim to unravel this and help you understand better what happens.
Essential keywords
First, there are some essential keywords I will like to define:
The Internet: The Internet is a network of networks that enables communication and data exchange between computers located in different regions through the TCP/IP protocol. Each device on the internet is identified and accessed by its IP address. By the way, TCP means Transmission Control Protocol while IP means Internet Protocol.
IP Address: This is a unique identifier for a device (computer) on a network. It is like the DNA of the device, no two machines have the same IP address. It is used to access and communicate with the device on a network.
Domain Name: This is the name we use to access specific websites or online services on the internet. Ideally, it is humanly readable and points to an IP address (i.e the unique identifier of a device on a network).
Put simply, domain names (or subdomains) are just easy names we use to identify computers on the internet instead of having to remember their IP address.
For example,
google.comis a domain name. Note thatwww.google.comis a subdomain that, ideally, points to the domain namegoogle.com, a web server, or a load balancer depending on the infrastructure.Endpoint: This is simply whatever comes after the domain name but before a question mark (those are URL query parameters). Say we have
www.google.com/search, the endpoint is simply/search. Say it iswww.google.com/search?q=how%20do%20fishes%20swim, the endpoint is still/search. In our case, we have justwww.google.com, wonder what our endpoint is? it's simply/.Domain Name System (DNS): This is a system that helps translate a domain name to an IP address. It receives a domain name and checks for the corresponding IP address that it points to, if it finds an IP address attached to the domain name, it returns that IP address, else it returns an error indicating that the domain name cannot be resolved. Note, resolving a domain name simply means getting the corresponding IP address for that domain name and the process is the same for a subdomain.
Load Balancer: This is simply software that helps share incoming requests between several web servers based on a predefined algorithm. The main aim of load balancers is to improve the performance, availability and reliability of web applications.
Web server: A web server is a piece of software application that runs on a computer and responds to incoming requests by responding with web resources such as HTML pages, images, videos, etc, or proxy it to an application server.
Application Server: An application server is a piece of software that provides an environment to perform server-side logic and complex database transactions. It also receives requests and may respond with web resources, or different forms of data. This is where interactions with the database and external APIs take place.
Understanding the workings
When you enter www.google.com in your browser, several things happen, they happen so fast that we don't even know they happened (except in cases of slow internet connections). I'll be iterating over these things in bullet points but first, you need to understand that when you request a page or a file or a video on the internet, you're accessing these resources from another computer on the internet. Those resources are stored on a computer on the internet and you're able to access it because that computer is online (i.e on the internet), if it goes offline (disconnected from the internet), you will no longer be able to access the resources on that computer. So, when you enter www.google.com in your browser, your browser needs the means to convert those words to something it can use to identify the computer that holds the resource you're trying to access, put simply, an IP address. Without knowing the IP address of the computer you're trying to access, it can do nothing. This is where the DNS comes in.
So, the first thing the browser does is it checks its DNS cache to see if it has a record for
www.google.comand its corresponding IP address, if it doesn't find a record for it, it then searches through the operating system's DNS cache before it proceeds to a DNS server, this server is ideally provided by our internet service provider. At this point, if it's still unable to resolve the domain name, it returns an error. In our case, it will return the IP address thatwww.google.compoints to. For a website as big as Google's search engine, this will ideally be the IP address of a load balancer.After getting the address of the load balancer, our browser now performs an SSL handshake with the load balancer, to ensure that data sent between the load balancer and our browser is encrypted. If this process is not successful, browsers like Chrome will return a page asking that you go back to the safe zone, or something like that, I can't remember vividly. It also provides the option to continue to interact with the site without SSL protection anyway, that's left to you to decide.
But say the handshake was successful, and our browser was able to establish a secure connection to the load balancer. It then sends a request (a GET request in this case) to the load balancer.
The load balancer is usually configured to serve requests to several web servers based on a specified algorithm. At this stage, the load balancer sends the request it received from our browser to one of the web servers on its list. Note that these web servers are also identified by their unique IP address and the request is sent to the selected server's IP address.
Ideally, web servers serve HTML documents as a response or they proxy these requests to an application server. The application server could be a Nestjs Application, a Django application, or an API, whatever it is, the web server proxies the request it received from the load balancer to the application server.
The application server then processes the request. Ideally, it would respond based on the type of request (GET, POST, CREATE, etc), the endpoint of the request, query parameters attached to the request, and many other things depending on how the application server was set up. In our case, we are hitting the
/endpoint with a GET request and no query parameters. Ideally, google's search engine's application server responds with an HTML document with a lot of javascript in it. This document is sent as a response from the application server to the web server, which then sends it to the load balancer.Once the load balancer receives the response, it sends it to the browser. When the browser receives the response, it checks the response header to see what kind of response was sent. In this case, it sees that it's an HTML document, so it parses the document to create the DOM tree, loads the associated javascript code into the DOM and then executes the javascript code to add interactivity and functionality to the page.
And bam! You get a nice-looking page with a search bar, waiting for you to enter your query.
Below is a simple flowchart that describes this process:
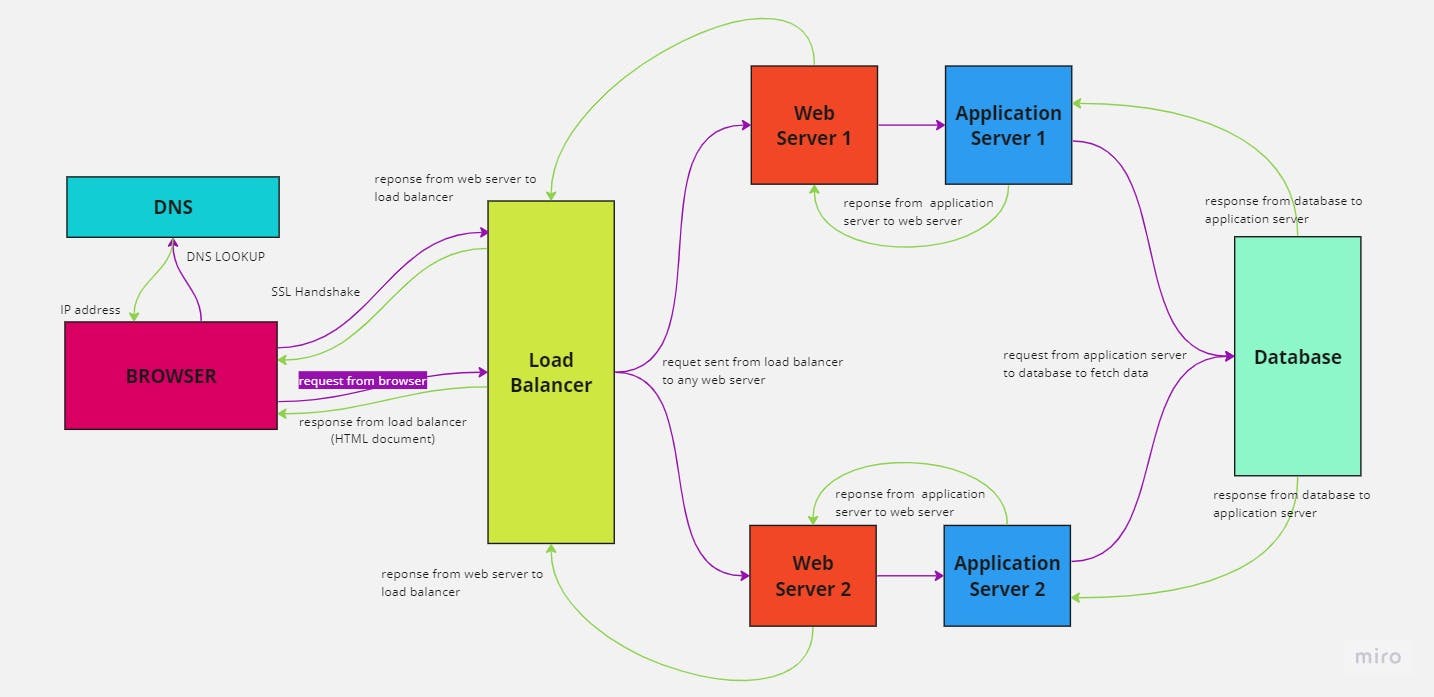
Actually, this is not perfect and I never started writing this with the mind of perfectly modelling Google's search engine's infrastructure. There may be other components like a firewall, a logging system, more web servers and databases and many more things that I didn't mention. The idea was simply to give a general idea of how the web works and how requests are processed and I hope I've been able to do that successfully. If you have any questions or comments, please drop them in the comment section.